Before we go into the CCIE SP INE BGP details, we must have good BGP foundation knowledge. The CCIE INE starts from the Basic BGP WorkFlow article
- BGP is currently in version 4 and it replaced the EGP in the 1990. When you see the EGP tag in your BGP table this is not „Exterior Protocol“ but the legacy EGP protocol which is not used anymore at all. So probably someone made some wrong configuration.
- BGP is designed to route IP through the Autonomous Systems.
- Two BGP Flavours: IBGP and EBGP.
- BGP uses TCP port 179 and maintanis NEIGHBOR or PEER Relationship. So BGP is application protocol and uses TCP for reliability.
- By default, BGP finds the best path to a network by using the best AS-PATH. And this is not good thing and should be tweaked in BGP. As we have in RIP the hop count in BGP this is the AS-PATH hop counts. We can change this via influencing the routing policy which can be configured by many BGP attributes we have.
- BGP Routing policies are configured using BGP attributes
- BGP converges slowly. Batch updates sent once every 5 seconds for IBGP Peers, once 30 second for EBGP peers.
Reason to RUN BGP
- You are a SP
- Redundant connections to two ISPs and you dont use the switch between your routers and their routers. Hence HSRP cannot be used. You can use however different IGP protocol for this, but this is how FIN CORE is designed.
The golden rule of BGP
„BGP does not enable one AS to send traffic to a neighbor AS intending that the traffic take a different route from that taken by traffic originating in the neighbor AS“ RFC 1771. In english: Dont tell me how to make my coffee. So one AS cannot tell other AS how it should route the traffic. You have control over your AS and you can influence routing in your AS, thats it. You cannot ultimately influence other ASes. However, there are some attributes which allows you to influence other ASes to change routing paths, but you cannot influence it ultimately, because the last word has always the AS where the routing is made. So hence you can suggest other ASes to change some routing path, but the ultimate decision is up to AS itself.
BGP Neighbor Relationship
- In BGP neighbors are manually configured. It doesnt send the broadcast and multicast messages and establish the adjacency by default. It is for security reasons because you dont want someone to suck you whole routing table – that could be a potential attack the one who sucked your routing table may influence your routing and you dont want that. In fact when you are going to run BGP with SP there are really careful and you must ensure them you wont mess with the routing table. There is big screening process for this.
- Neighbors start in IDLE state (show ip bgp summary)
- Connect state – BGP 3-way handshake between peers
- ACTIVE – sounds like good thing but it is very bad state. This means that the BGP is actively trying to establish the bgp but something is preventing from forming.
- OPEN SENT – your router has sent an open sesssion message to the neighbor you manually configured. OPEN SENT means that you just sent the open message and you are waiting to receive the confirmation.
- OPEN CONFIRMED – router has received confirmation to the OPEN SENT message from neighbor.
- ESTABLISHED – when everything is OK this is the last stage. However you wont be able to see this stage because when is everything ok and established you just see in the show ip bgp summary other things like link counts, hold timer,… So if you dont see any of these stages and you dont see established thats probably good thing 😉
- HELLO Messages are sent once every 60 secs with a holdown of 180 seconds.
- Capable of MD5 Auth. BGP is slow, yo!
Rule of Synchronization
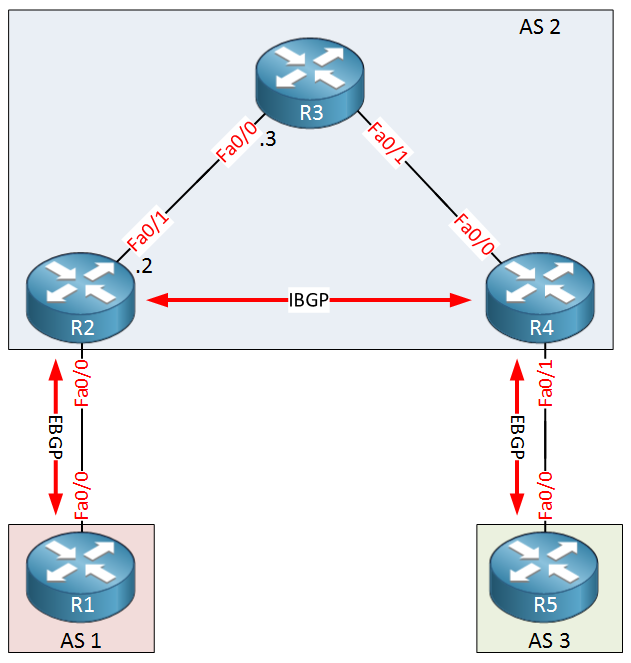
Routes learned via BGP must be validated by the interior routing table before they can be advertised to remote peers. BGP synchronization is an old rule from the days where we didn’t run IBGP on all routers within a transit AS. In short, BGP will not advertise something that it learns from an IBGP neighbor to an EBGP neighbor if the prefix can’t be validated in its IGP. Check the figure below. AS 2 is the transit AS between AS1 and AS3. If the IBGP would run just betwen the R2 and R4 then the R3 would not know the BGP route. The BGP routes will be known just by R2 and R4. Then when you want route the actual traffic from AS3 to AS1 via AS2, the R3 would drop the traffic because it doesnt have the route. That will create the black hole in the network.
Note that this sort of desing below is very rare and in most situation the IBGP routers will be connected directly or the R3 as well will be running the IBGP. However the rule of synchronization would still apply even though you have the bgp everywhere.
So from IBGP to EBGP there is the fucking SYNC rule. So if everyone is running the BGP it will be save to turn the SYNC rule off.
So the Sync rule is here to protect you from black holing if you dont have full mesh IBGP in your network and the Split Horizon rule below is here to protect you if you indeed have full IBGP mesh and hence there is a loop. HAHA
Rule of Split Horizon
Routes learned via IBGP will never be sent to antoher IBGP peer. This can form a loop in your topology if you have IBGP full mesh.
So the Sync rule is here to protect you from black holing if you dont have full mesh IBGP in your network and the Split Horizon rule is here to protect you if you indeed have full IBGP mesh and hence there is a loop. HAHA
Basically you would not run IBGP full mesh in your network, but you create something called route-reflector. Route reflector basically disables the split horizon rule and sends the IBGP routes to every router it has adjacency with.
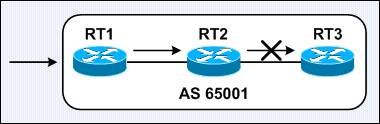
AS-PATH Attribute LOOP Prevention
- for EBGP there is AS-Path attribute which states that router will drop BGP advertisement when it sees it own AS number in AS path attribute
EBGP Multihop
The EBGP must be directly connected to be able establish the session. This is due to restriction in BGP. EBGP packets has TTL value of 1. When peering with external neighbor, the only address you can peer without any bgp tuning is the address of directly connected interface. If you want to use loopback interface, you have to tweak the bgp via command „neighbor xxxx ebgp-multihop ttl
Defining the Source IP Address
The BGP neighbor statement tells the BGP process the destination IP address of each update packet. The router must decide which source address will use for each routing update. By default the router will use the source IP address of its interface where the neighbor is located by simple checking the routing where neighbor is located.
However you want to use loopback interfaces as Router-ID for bgp sessions establishment. Why? Because you have many benefits from it. When the router interface goes down and your peering is established with IP of that interface the whole sessions will be down and no backup path can be used. If however you use loopback interface that can be accessible via more than one path and failover path can be chosen by simple routing in the network. Cool righ. Realize this is simple TCP session and when you are creating these sessions against the loopback interface you are not dependent on the physical interfaces and its state. Also creating BGP session against all the physical interfaces can be pain in the ass! yeah!
To fix this you use the command „neighbor XXXX update-source looopback0“
Changing the Next HOP attribute
Because BGP is routing protocol designed on Internet to route between the ASes, when BGP update is received from EBGP peer and then it is propagated to the IBGP peer the NEXT HOP attribute is by default not changed and still points to the EBGP peer. To change this default behaviour you need to configure the „neighbor XXXX next-hop-self“ command.
Resetting the BGP Session
BGP can potentially handle huge volumes of routing information. When a BGP policy configuration change occurs (route-policy, attributes), the router cannot go through the huge table of BGP information and recalculate which entry is no longer valid in the local table. Because of this the new policy is enforced only to the new BGP updates after the policy change. If you want these changes applied immediately you must trigger an update to force the router to let all routes pass through the new filter.
If the filter is applied for outgoing routes you must resend the BGP table through the new filter. If the filter is applied for inbound routes, the router needs neighbor to resend its BGP table so it passes through the new filter. There are three ways to trigger an update:
- Hard reset – the worst way to trigger an update is to force hard reset, ie TCP reset. This will disrupt the routing because when you tear down the TCP session, hence you clear whole routing table. You execute the hard reset via command clear ip bgp neighbor-address
- Soft reset
- Soft reset for outbound sessions – for outbound session you dont need hard reset. You can send the whole routing table to all of your neighbors with the „withdrawal“ statements.
- Soft reset for inbound session – this is little bit hard without the hard reset as you cant force the neighbor to resend its routing table. What you need to do is to store the neighbor routing table into the memory. To do that you must preconfigure the neighbor with command „neighbor XXXX soft-reconfiguration inbound“ Then the routing table for this neighbor is always stored in your memory, hence when you apply new policy and execute command clear ip bgp neighbor-address soft in the new filters are applied for the table stored in your memory
- Route refresh (dynamic inbound soft reset) – Cisco IOS introduces the route refresh enhancement feature to provide automatic support for soft inbound reset without need to store the whole routing table for the neighbor in the memory. This method also doesnt require any pre-configuration for neighbor like in above. The clear ip bgp neighbor-address soft in is the only command you need. Via this command you send the route-refresh message and force the neighbor to resend the routing table. There is no other way how to force the neighbor to send its whole table only the hard reset and route refresh.
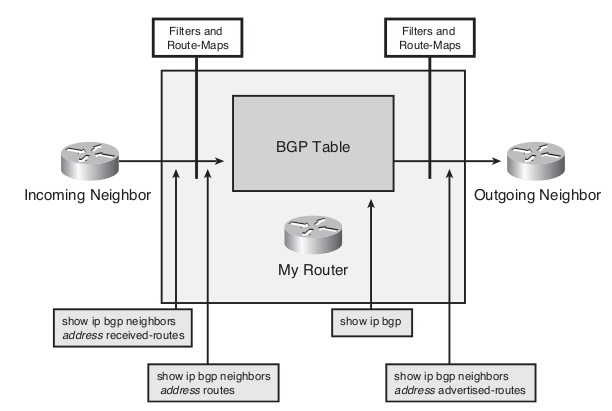
When your routers are using soft reset functionality (not the route refresh) you can use the following commands which can be extremely useful for policy troubleshooting:
- „show ip bgp neighbors neighbor-address received-routes“ – display all received routes from neighbor. All accepted and rejected
- „show ip bgp neighbors neighbor-address routes“ – display all routes that are received and accepted from specified neighbor. It shows the routes after the inbound policy applied 😉
- „show ip bgp“ – display entries in the BGP table
- „show ip bgp neighbors neighbor-address advertised-routes“ – display the routes after the outbound policy filter applied