Historically, server I/O connectivity to storage, local area networks, and other servers have been accommodated by hardware and software specifically designed and dedicated to the application, each with different traffic characteristics and handling requirements. Server access to storage in enterprises has been largely satisfied by Storage Area Networks (SAN) based on Fibre Channel. Server access to networking devices is almost exclusively satisfied by local networks (LAN) based on Ethernet. Lastly, server-to-server connectivity, or inter-process communication (IPC) for high performance computing (HPC), is being satisfied with InfiniBand. While each of these technologies serves their application needs very well, the specialization results in the need for enterprise servers to support multiple dedicated specialized networks with unique dedicated hardware. All these networks in the data center often require physically redundant backup connections, which compounds the problem and introduces double the amount of NICs, HBAs, and HCAs into the network. Thats why more advanced ethernet controlers and consolidated I/O adapters called converged network adapters (CNAs) have been invented.
Dynamic load balancing requires the ability to easily move workloads across multiple generations of platforms without disrupting services. Centralized storage becomes a key requirement for virtualization usage models. 10GE (10 Gigabit Ethernet) supports storage implementations of iSCSI SAN as well as NAS today. Fibre Channel over Ethernet (FCoE) solutions extend the 10GE to seamlessly interoperate with existing Fibre Channel SAN installations. Consolidating storage traffic over 10GE using FCoE simplifies the network and provides a cost effective mean to enable virtualization usage.
Today, the 10GE NIC market is predominately served with stand-alone adapter cards. These cards plug into the PCIe bus expansion slots of a server to provide 10GE connectivity. Mezzanine form-factor NICs are appropriate for server blades that are installed into blade servers. In this case, there is not a standard PCIe slot. The mezzanine is a daughter card with a proprietary connector, size, and power consumption. While the connector is proprietary, the protocol spoken is always PCIe.
In the next couple of years, OEMs will start providing 10GE LAN on Motherboard ( LOM) solutions. LOM solutions implement LAN chipset integrated onto the PC motherboard thus freeing up valuable PCI slots. LOM implementations are less expensive than adapter or mezzanine cards and also implement effective management technologies that require signal transfer directly to the system board. With LOM implementation, 10GE will be pervasive; every server will ship with an on-board 10GE controller. The tipping point for 10GE will come when data centers refresh their environment with the new Intel® Xeon® 5500 class of server products.
Next sections describes most advanced Ethernet Controllers/CNAs from TOP manufacters.
Intel® 82598 10 Gigabit Ethernet Controller (Oplin)
The 82598 was designed to offer outstanding performance and power efficiency, while at the same time providing support for multi- core processors, virtualization, and unifi ed I/O over a broad range of operating systems and virtualization hypervisors. It can be installed in PCIe form-factor cards, or in mezzanine cards or directly on the server motherboard ( LOM).
The 82598 introduces new networking features to support multi-core processors. Supported features include:
- Message Signaled Interrupts-Extended (MSI-X) that distributes network controller interrupts to multiple CPUs and cores. By spreading out interrupts, the system responds to networking interrupts more efficiently, resulting in better CPU utilization and application performance. What are MSI? All the interrupts perform the same function: a notification about some event which is sent from one (PCIe) agent to another. Why do we call these notifications „interrupts“? Well, in general (not always though), the micro-processor which gets interrupted would stop its current activity, save the state of this activity in some manner, and switch its attention to handling the interrupt (by means of executing Interrupt Servicing Routine; in short – ISR). We say that the arrival of this notification interrupted the normal flow of micro-processor, hence the name „interrupt“. In the early days, all interrupts were just wires: each event which had to be communicated between agents was represented by a single wire. However, as the number of such event grew, the number of wires which had to be routed on a chip became huge. The introduction of standardized interconnects (PCI, PCIe, and more) between HW modules allowed a new concept for interrupts delivery to be used – a Message Signaled Interrupt (MSI). Why MSIs are better than just wires? Well, engineers though that if there is anyway an interconnect which allows for exchange of generic messages between agents, then it will be a waste of space to add unnecessary wires on top of it – you can use the existing interconnect in order to exchange special messages, just make sure that all agents treat these special messages as interrupts. PCI MSIs were introduced in PCI2.2 (Wiki) as an alternative to the regular interrupts, and they became mandatory in PCIe. MSI-X is just an extension of PCI MSIs in PCIe – they serve the same function, but can carry more information and are more flexible. NOTE: PCIe support both MSI and MSI-X.
- Multiple Tx/Rx queues: A hardware feature that segments network traffic into multiple streams that are then assigned to different CPUs and cores in the system. This enables the system to process the traffic in parallel for improved overall system throughput and utilization.
- Low latency enables the server adapter to run a variety of protocols while meeting the needs of the vast majority of applications in HPC clusters and grid computing.
- Intel® QuickData Technology, which enables data copy by the chipset instead of the CPU, and Direct Cache Access (DCA) that enables the CPU to pre-fetch data, thereby avoiding cache misses and improving application response times.
- The 82598 includes support for the Intel® Virtualization Technology for Connectivity (Intel® VT-c), to reduce the need for computeintensive software translations between the guest and host OSes. An important assist for virtualized environments is the Virtual Machine Data Queues (VMDq)
Intel® 82599 10 Gigabit Ethernet Controller (Niantic)
The 82599 is the second-generation PCIe Gen-2-based 10GE controller from Intel. The 82599 delivers enhanced performance by including advanced scalability features such as Receive Side Coalescing (RSC) and Intel® Flow Director Technology. The 82599 delivers virtualization capabilities implementing Single Root I/O virtualization (SR-IOV, see “SR-IOV” in Chapter 3, page 83). Finally, the 82599 delivers advanced capabilities for unified network including support for iSCSI, NAS, and FCoE.
Most advanced functionalities:
- RSC – described below
- Intel Flow Director – described below
- TCO (TCP offload). CPU does not need to deal with layer 4. It is completely offloaded to NIC
- Rx/Tx Queues and Rx Filtering
- MSI Interrupts
- Packet Filtering (MAC address, VLAN, …)
- Mirroring to other VMs. Various mirroring modes are supported
- Packet Switching. 82599 forward transmit packets from transmit queue to Rx queue to support VM-VM communication.
- Traffic shaping
- SR-IOV – single root I/O Virtualization
- PFC (priority flow control)
- DCB (data center bridging)
- SCSCI offloaded
- FC CRC chech offloaded. FC CRC calculation is one of the most CPU intensive tasks.
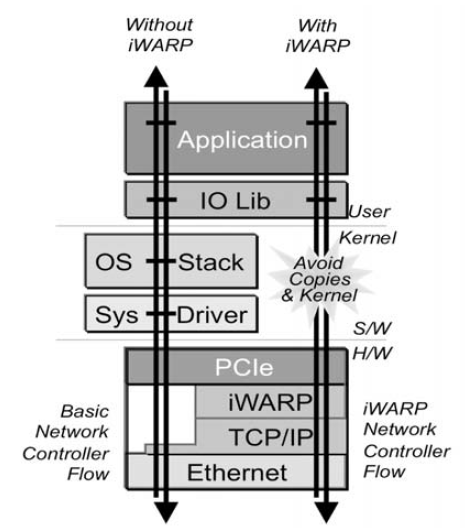
DDP (Direct Data Placement). Relatec to RDMA (Remote Director Memory Access). The Direct Data Placement protocol provides information to Place the incoming data directly into an upper layer protocol’s receive buffer without intermediate buffers. This removes excess CPU and memory utilization associated with transferring data through the intermediate buffers.
RSC is stateless offload technology that helps reduce CPU utilization for network processing on the receive side by offloading tasks from the CPU to an RSC-capable network adapter. CPU saturation due to networking-related processing can limit server scalability. This problem in turn reduces the transaction rate, raw throughput, and efficiency. RSC enables an RSC-capable network interface card to do the following:
- Parse multiple TCP/IP packets and strip the headers from the packets while preserving the payload of each packet.
- Join the combined payloads of the multiple packets into one packet.
- Send the single packet, which contains the payload of multiple packets, to the network stack for subsequent delivery to applications.
Intel Flow Director technology put the specific flow for specific packet to correct CORE. Before all flows was handled just by one CORE. Then Microsoft came with their functionality called RSS to distribute flows to other CORES. However the flows were put to wrong CORES, so then the CORES had to exchange the flow.
Intel’s NetEffect™ iWARP Controller (NE020)
The NE020 is a PCIe Gen-1-based controller that implements the iWARP protocol on top of hardware TCP engine, enabling an RDMA over Ethernet solution.
iWARP/RDMA enables very low-latency communication for High Performance Computing (HPC) and other ultra-low-latency workloads.
Converged Network Adapters (CNAs)
Converged Network Adapters is a term used by some vendors to indicate a newgeneration of consolidated I/O adapters that include features previously present in HBAs, NICs, and HCAs.
Players in this new consolidated I/O market are the classical Ethernet NIC vendors that are adding storage capabilities to their devices and HBA vendors that are adding Ethernet support. CNAs offer several key benefits over conventional application unique adapters, including the following:
- Fewer total adapters needed
- Less power consumption and cooling
- Reduced and simplified cabling
- Full support for PFC (802.1QBB), ETS (802.1Qaz), DCBX (802.1Qaz)
- Boot from LAN/SAN
- Full FCoE hardware offload
Cisco Palo CNA
Palo is a CNA developed by Cisco® Systems. It is currently supported only on the UCS. When used in conjunction with UCS servers, Palo provides several important system-level features:
- I/O consolidation and Unified Fabric
- DCB-compliant Ethernet interfaces
- Capability to support active/active and active/standby
- Capability to be fully configured through the network
- Capability to create I/O devices on demand to better support
virtualization - Capability to support kernel and hypervisor bypass
- Low latency and high bandwidth
- SRIOV compliant hardware
- Native support for VNTag
- Native support for FCoE
- MSI
- RSS
- LSO (large segment offload also called TCP Segment Offload – TSO) – This belongs to TOE umbrella (TCP offload Engine). When a system needs to send large chunks of data out over a computer network, the chunks first need breaking down into smaller segments that can pass through all the network elements like routers and switches between the source and destination computers. This process is referred to as segmentation. Often the TCP protocol in the host computer performs this segmentation. Offloading this work to the NIC is called TCP segmentation offload(TSO). Check the picture, it shows TOE.
- VMDirectPath
- and others
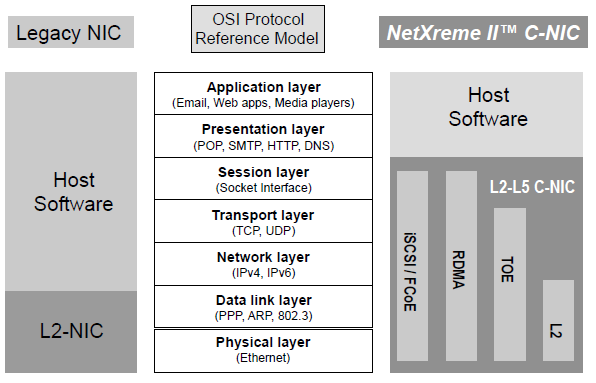
Then there are other Vendors with CNAs like Emulex, QLogic or Broadcom. All more or less supports same feautures, but you better check if it supports what you need (for example VNTag). QLogic is known by market leader NIC in the SAN field. It has the best performance (according to book from 2010).