First servers in Data Centers where the stand-alone servers with limited computing, storage, power… Many times they had proprietary form factor. To overcome scalability and power limitations there are two approaches:
- Scale UP – Scale-up, aka scale vertically, is a term used to indicate a scaling strategy based on increasing the computing power of a single server by adding resources in term of more processors, memory, I/O devices, etc.
- Scale OUT – Scale-out, aka scale horizontally, is a term used to indicate a scaling strategy based on increasing the number of servers.
Scale UP vs Scale OUT
Scale-up requires dedicated and more expensive hardware and provides a limited number of operating system environments, and there are limitations on the amount of total load that a server can support. It has the advantage of having few management points and a good utilization of resources and therefore it tends to be more power and cooling efficient than the scale-out model. Scale-out dedicates each server to a specific application. Each application is limited by the capacity of a single node, but each server can run the most appropriate OS for the application with the appropriate patches applied. There is no application interference and application performance is very deterministic. This approach clearly explodes the number of servers and it increases the management complexity.
Rack Optimized Servers
With scale-out constantly increasing the number of servers, the need to optimize their size, airflow, connections, and to rationalize installation becomes obvious. Rack-optimized servers were the first attempt to solve this problem. Also known as rack-mounted servers, they fit in 19-inch wide racks and their height is specified in term of Rack Unit (RU). The benefits of this approach are rational space utilization and high flexibility, the relative large server size allows adopting the latest processor with a larger memory, and several I/O slots. The weaknesses are in the lack of cabling rationalization, in the serviceability that is not easy, and in the lack of power and cooling efficiency, since each server has its own power supplies and fans. Rack-mounted servers are just a simple repackaging of conventional servers in a form factor that allows installing more servers per square foot of data center floor, but without significant differences in functionality.
Blade Servers
Blade servers were introduced as a way to optimize cabling and power efficiency of servers compared to rack mounted. Blade server chassis are 6 to 12 RUs and can host 6 to 16 computing blades, plus a variety of I/O modules, power supplies, fans, and chassis management CPUs. Blade server advantages are shared chassis infrastructure (mainly power and cooling), rationalization in cabling, and the capability to monitor the shared infrastructure. The number of management points is reduced from one per server to one per chassis.
Server Sprawl
Before Virtualization came to its full strength most servers run a single OS (commonly some form of Windows® or Linux®) and a single application per server. This deployment model leads to “server sprawl”, i.e., a constantly increasing number of servers with an extremely low CPU utilization, as low as 5% to 10% average utilization. This implies a lot of waste in space, power, and cooling. The benefits of this deployment model are isolation (each application has guaranteed resources), flexibility (almost any OS/application can be started on any server), and simplicity (each application has a dedicated server with the most appropriate OS version). Each server is a managed object, and since each server runs a single application, each application is a managed object.
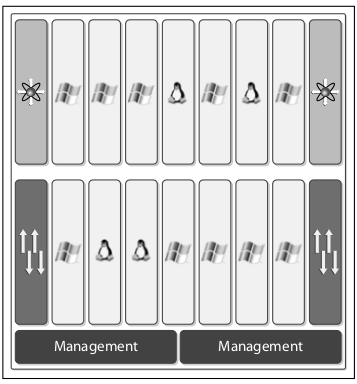
Nonetheless, server sprawl is becoming rapidly unacceptable due to the waste of space, power, and cooling. In addition, the management of all these servers is an administrator nightmare as well as very expensive.
Virtualization
Virtualization is one of key technologies used to reduce server sprawl and it has been heavily adopted by organizations throughout the world. As opposed to the chassis being a container, with virtualization a server is a container of multiple logical servers. The advantages of server virtualization are utilization, mobility, and availability.
Unified Computing System
Cisco’s definition for Unified Computing is: “Unified Computing unifies network virtualization, storage virtualization, and server virtualization into one, within open industry standard technologies and with the network as the platform.”
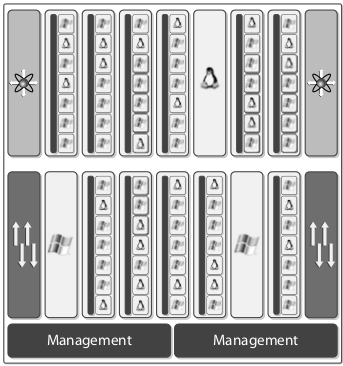
UCS is composed of fabric interconnects that aggregate a set of blade chassis and rack servers. Compared to blade servers, it is an innovative architecture. It removes unnecessary switches, adapters, and management modules—i.e., it has 1/3 less infrastructure compared to classical blade servers. This results in less power and cooling and fewer management points, which leads to an increased reliability. Compare the pictures below. First is blade chassis with UCS and second is without the UCS. The savings for UCS are obvious.


The most important technology innovations introduced in UCS are:
- Embedded management: UCS does not require a separate management server, since it has an embedded management processor that has global visibility on all the elements that constitute a UCS. This guarantees coordinated control and provides integrated management and diagnostics.
- Unified Fabric: UCS is the first server completely designed around the concept of Unified Fabric. This is important since different applications have different I/O requirements. Without Unified Fabric, it is difficult to move applications from one server to another while also preserving the appropriate I/O requirement. Unified Fabric not only covers LAN, SAN, and HPC, but also the management network.
- Optimized virtualized environment: Designed to support a large number of virtual machines not only from the point of view of scale, but also from policy enforcement, mobility, control, and diagnostics
- Fewer servers with more memory: The UCS computing blades using Cisco Memory Expansion Technology can support up to four times more memory when compared to competing servers with the same processor. More memory enables faster database servers and more virtual machines per server, thus increasing CPU utilization. Fewer CPUs with more utilization lower the cost of software licenses.
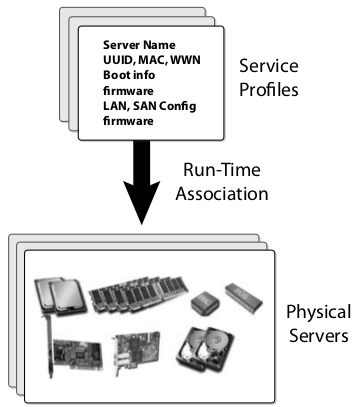
- Stateless computing: Server attributes are no longer tied to physical hardware that enables seamless server mobility. The blades and the blade enclosures are completely stateless. UCS also puts a lot of attention on network boot (LAN or SAN) with the boot order configurable as a part of the service profile.
- Hybrid system: A UCS can be composed of a mixture of blades and rack servers and they can all be managed by the UCS Manager.
At the core of the UCS architecture is the concept of a “Service Profile”—i.e., a template that contains the complete definition of a service including server, network, and storage attributes. Physical servers in UCS are totally anonymous and they get a personality when a service profile is instantiated on them.